在經過一連串的嚴重 P0 事件簿後,不知道讀者對處理相關事件是否更有概念了呢?在「系統警報概論」這篇文中曾有初步提到過,因為 P0 事件的當下資訊非常多且雜亂,因此任何能夠協助值班工程師判斷狀況的工作都會受 SRE 所重視。
比如說,在「特殊監控系統」系列文中的的「第三方服務監控」就是其中一個可以幫助值班工程師判斷警報的工具。概念上非常單純,就是在警報發生或使用者品報異常的情況下,透過該監控系統來協助判斷事件的成因是來自我們的系統還是客戶的系統。
為第三方服務掛上監控系統是比較大的工作,因此獨立來討論。但針對警報的改善也有需要細節上或微小的改動,而且這些改動也不單純是針對 P0 等級的警報。這一篇文章,就會專門針對這件事情向各位分享,筆者在入職一年來有做過什麼與警報改善相關的工作。
在「系統警報概論」中曾經有提到過,警報設定的一個重要前提,就是在響起來的當下,看到的值班工程師必須要有事情可以做。然而,我們經過一連串的警報事件後,發現有部分警報其實並沒有符合這個要件,這個警報就是單一一台資料庫伺服器的 CPU 使用量超過 90% 的警報。
這個警報雖然不常發生(不擾民),但因為該專案共有 3 台資料庫伺服器做為最低台數的保證,因此當只有一台發生警報的時候,其實服務本身在使用上並不一定會受到影響,或頂多只有少數的使用者感覺網站比較緩慢而已。
而最重要的則是,在警報發生的當下,被叫醒的工程師從頭到尾只能看著自動擴展機制開啟新機器分擔流量之後,回報一聲系統回歸正常而已。但既然自動擴展會協助我們完成所有事情的話,根本就不會需要額外花費保貴的人力,不是嗎?
因為這個警報本身對專案本身的危險程度不到非常高,而且工程師在警報當下也沒有事情可做,所以我們就開始著手思考如何改善這個警報的設計。
最後,我們決定將原本的警報放入 P1 等級的頻道裡面,並設立了一個「3 台資料伺服器 CPU 全部超過 90%」時的 P0 警報,而實際上該 P0 警報本質上就是 CloudWatch Composite Alarm。
「將原本的警報放入 P1 等級的頻道裡面」主要還是因為,CPU 使用量超過 90% 仍然是一個不正常的現象,因此是一個需要在上班時注意到並處理的狀況。比如說,透過 AWS RDS 的 Performance Insight 可以觀察到不同 query 的使用量,將使用大量資源的 query 提交給申端工程師進行最佳化的動作,就會是其中一個可能性。
不過,「3 台資料伺服器 CPU 全部超過 90%」的時候,工程師到底可以做什麼呢?事實上在大部分的狀況下,工程師還是只能「等待自動擴展作業」的進行。但全部資料庫伺服器都發生異常的狀況下,值班工程師還是需要先確認系統現在是否真的遇到除了流量過高之外的界常狀況,因此仍然算是有符合一開始「要有事情可以做」的原則。而實際上這種警報相較於之前的警報,發生頻率已經下降很多,也比較不會像一開始描述般地擾民了。
由於公司本身業務比較繁雜,再加上各種歷史因素,我們某些專案雖然自己會有一個主要的 AWS 帳號,但在使用某些服務的時候,會與另外一些不同的 AWS 帳號中的資源進行串接。也因為其它帳號中的資源可用性,會直接或間接影響專案的可用性,因此針對那些帳號中資源的監控也會是 SRE 的一個重要工作之一。
在過去,我們是透過直接在該 AWS 帳號中建立相關警報的方式來解決這個問題。但隨著時間的演進以及專案的複雜化,我們逐漸發現這種做法在管理上的困難。比如說,某帳號中既有為 A 專案服務的資源,也有為 B 專案服務的資源,或甚至某個資源同時為這兩個不同的專案服務。在這個狀況下,我們要在該帳號中同時建立為了 A 專案和 B 專案而設立的監控系統,或是一個資源因為專案需求不同,而同時有兩個不同的監控系統。這些都造成了各種混亂,並大幅提升了後續維護上的困難。
幸運的是, CloudWatch 有推出一個跨帳號監控的功能(文件),該功能主要是經過一連串帳號分享的設定之後,將 A 帳號的 CloudWatch Metrics 全部送到 B 帳號。在串接完成後,就可以直接在 B 帳號看到所有 A 帳號裡面資源的 CloudWatch Metrics 資訊。既然有 metrics ,那後續建立相關的 CloudWatch Alarm 就不會是什麼問題。
透過這個功能,我們現在成功把監控和警報統一放在專案的 AWS 帳號中管理。雖然 AWS 推出該功能看起來是為了讓客戶建立一個監控用的帳號,並將其它帳號中的監控資訊集體往該帳號傳送,但目前我們還是先以專案為單位來進行監控。也許未來的改善也會朝這個方向也說不定。
另外,因為會建立一個新的帳號來管理某些資源,通常也是因為有一個特定的團隊在專門開發或維護相關資源。也因為該資源本身有一些特殊專業性,不是我們平常熟知的 EC2 、 RDS 、ElastiCache 之類的服務,因此在監控這些服務的時候,也常常會需要和其它團隊的工程師協調,向他們諮詢以理解服務異常的定義,在警報發生後有後續行動建議的討論前提下來建立相關的警報。
雜訊刪減的概念非常單純好理解,就是把不需要的警報雜訊給去除掉的工作。所謂雜訊,其實也就是收到後不清楚後續行動,且因為數量龐大而影響判斷的警報訊息。因此刪減相關雜訊其實也符合前面有提到過「工程師要有事情可以做」的要求。
在「系統警報概論」中曾經有提到, P1 的頻道訊息是上班後要關心的訊息,但在過去一段時間中,在筆者負責的專案裡,其實 P1 頻道裡面堆放了各種雜訊,也就是響了之後不確定要做什麼的訊息。當時的狀況,有點像是把除了正式環境以下的其它環境都往這裡丟,因此該頻道裡面充斥著非正式環境的各種訊息,以及許多從其它 AWS 帳號傳來的資訊(也就是前一小節中提到的,建立在其它帳號中的資源的監控)。
而筆者會開始重新整理,主要還是因為,我們某個負責收日誌的伺服器因為記憶體過量而故障。我們一直到事發過後很久才發現,但其實相關警報早在之前就已經被送到 P1 頻道,只是被其它雜訊給淹沒了。事實上,筆者還曾經一度以為我們沒有設定相關監控,還因此與產品經理協商,要花額外資源來建立相關監控警報呢。
為了避免該狀況再度發生,筆者因此決定要花時間重新整理 P1 頻道的警報。再與團隊多次協商之後,最後直接刪除了針對非正式環境的監控,將單純記錄系統日誌的訊息移到 normal 頻道,並將「沒有後續行動,但工程師要稍微知道一下」的訊息移到 P2。在 P1 頻道中保留那些「確實要在上班時處理」的警報。
整理乾淨之後, P1 頻道裡面的訊息,大概是2-3天才會出現一個訊息了,變得相當好維護,也終於不再只是沒有人會看的裝飾用頻道了。事實上,前兩小節中有提到,單一資料庫的 CPU 使用量過高的警報,也是在 P1 頻道被整理乾淨後才被移進去的。
在「前言 & 基本監控系統」中有提到過我們基本監控系統,為了喚醒讀者的記憶,請再參考一次下圖:
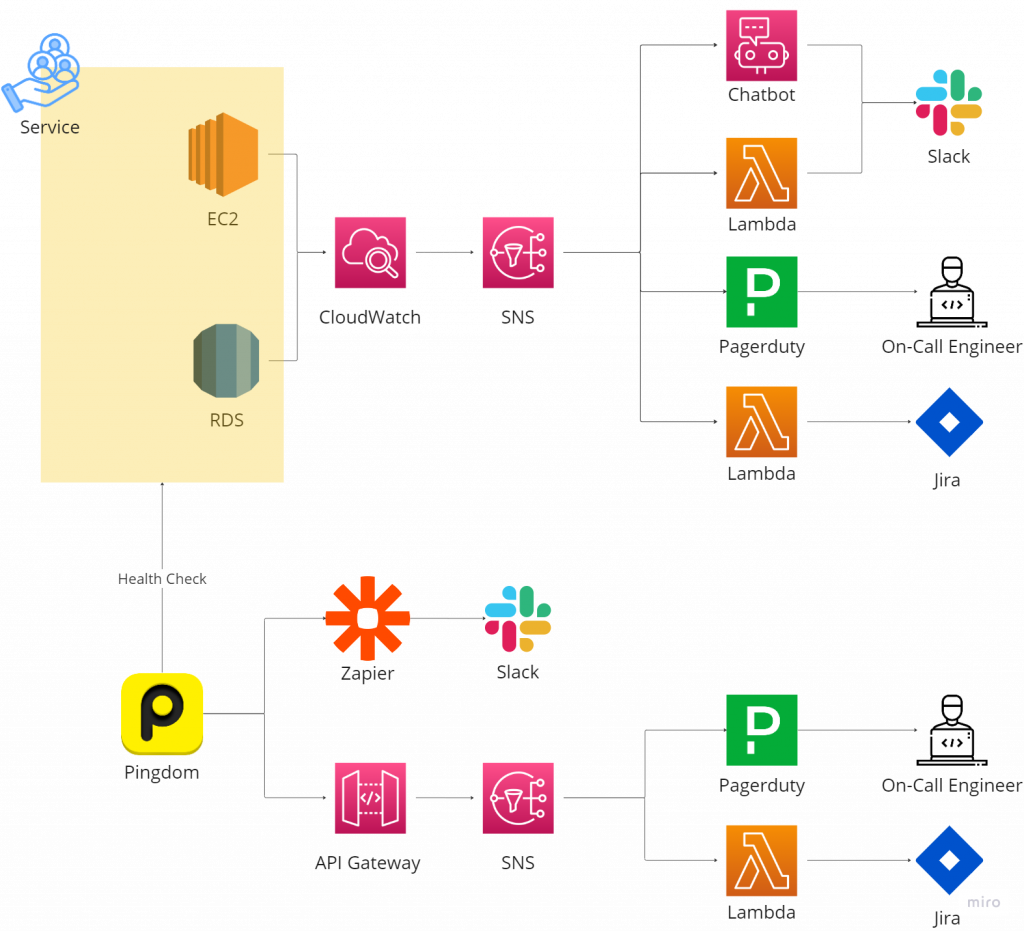
在 CloudWatch Alarm 被觸發被把訊息送到 SNS 進行 fan-out 之後,後續接訊息並傳到 Slack 的總共有兩種路方式。一種是 AWS Lambda ,另一種則是 AWS Chatbot。
這邊也許可以讓讀者試著想想看,這兩者的差異,以及誰好誰壞?
在一開始 AWS Chatbot 還沒有被推出或普及之前,我們主要是透過 AWS Lambda 來進行訊息的整理以及再發送到 Slack 的頻道。這絕對不是一種比較差的方式,而且 AWS Lambda 提供了非常有彈性而可以客製化訊息內容的方式。比如說,訊息本身可以有「@channel」的功能,這是 AWS Chatbot 所不具備的功能。如下圖:
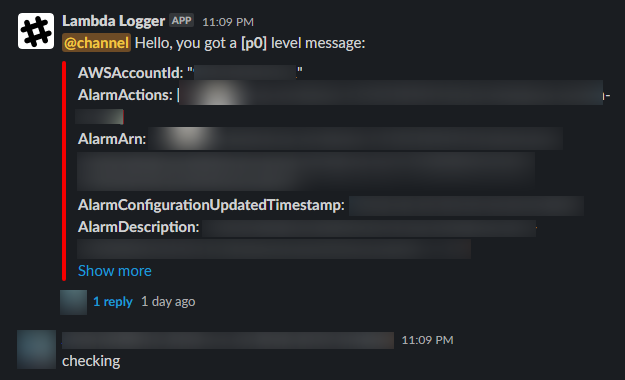
然而,透過實際寫程式來客製化訊息內容非常方便,但程式本身卻增加了不少維運上的成本。由於我們大部分的自動化工具都是以 Python 寫成的,因此當 Python 版本 EOL 的時候,我們就需要一併更新 Lambda 的 runtime 版本。事實上,筆者在剛入職的時候,就接過一些要從 Python 2 更新為 Python 3 的 Lambda Function ,它們甚至連 print 後面有沒有刮號都不一樣,在當時吃了不少苦頭。
因此,在比較新的監控系統中,我們都盡可能地串接 AWS Chatbot ,並儘可能在其它類似的狀況中,儘可能不要選擇自己透過 Lambda 寫程式的解決方案。不過因為 Chatbot 本身沒有「@channel」的功能,因此當初也花了一些時間與產品經理溝通,來獲得他們的理解。如下圖(這也在「系統警報概論」中有呈現給讀者看過):
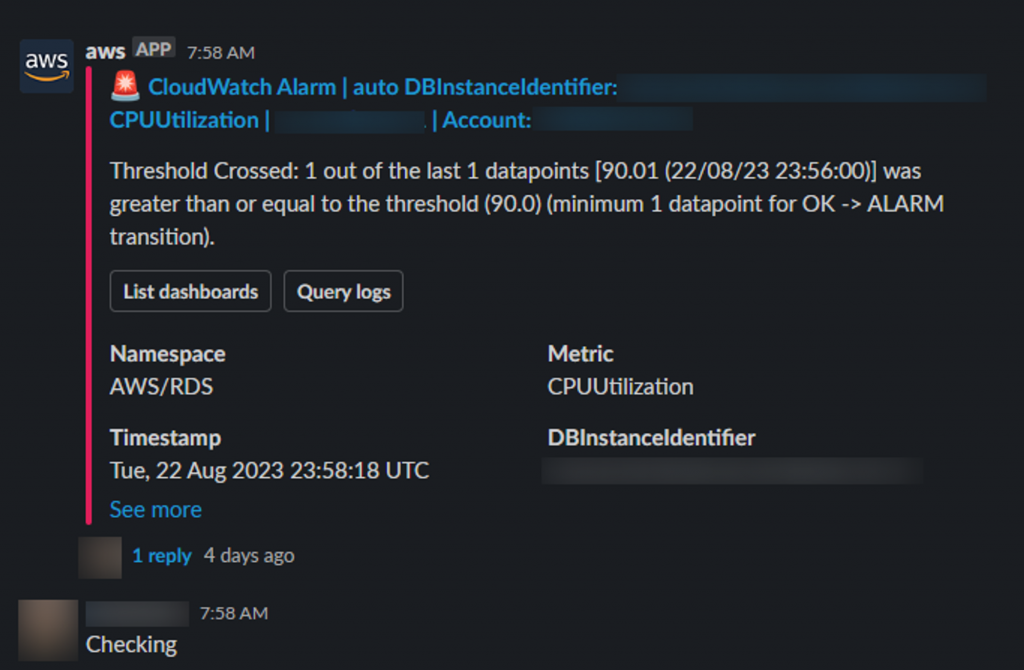
總而言之,能夠自己寫程式是最有彈性的,但在與後續維護成本之間,我們仍然在尋找一個比較良好的平衡點。
警報改善接續了嚴重 P0 事件簿,到這裡也算是告一個段落了。處理 P0 事件只佔據 SRE 工作的一小部分,警報的改善工作也不是天天在做。 SRE 最主要的工作還是在日常維運的事務。不過,警報改善的工作讓筆首重新意識並理解我們設置警報的出發點,而每次嚴重 P0 事件的發生,也都能讓筆者學到非常多知識,對於累積經驗也有相當大的助益。
將這部分的資訊分享給讀者,也希望這一系列的分享能夠讓各位有所收穫。

